{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
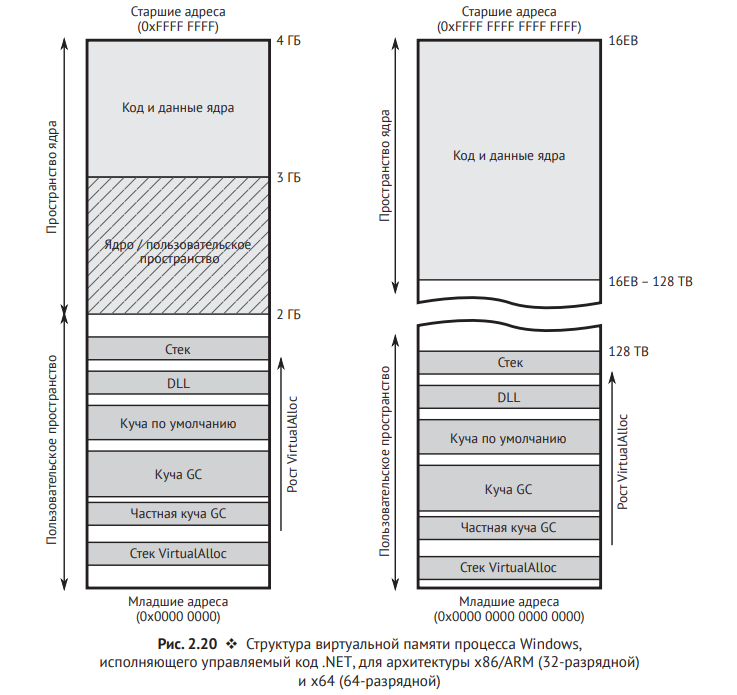
Организация данных
https://habr.com/ru/articles/813781/ источник
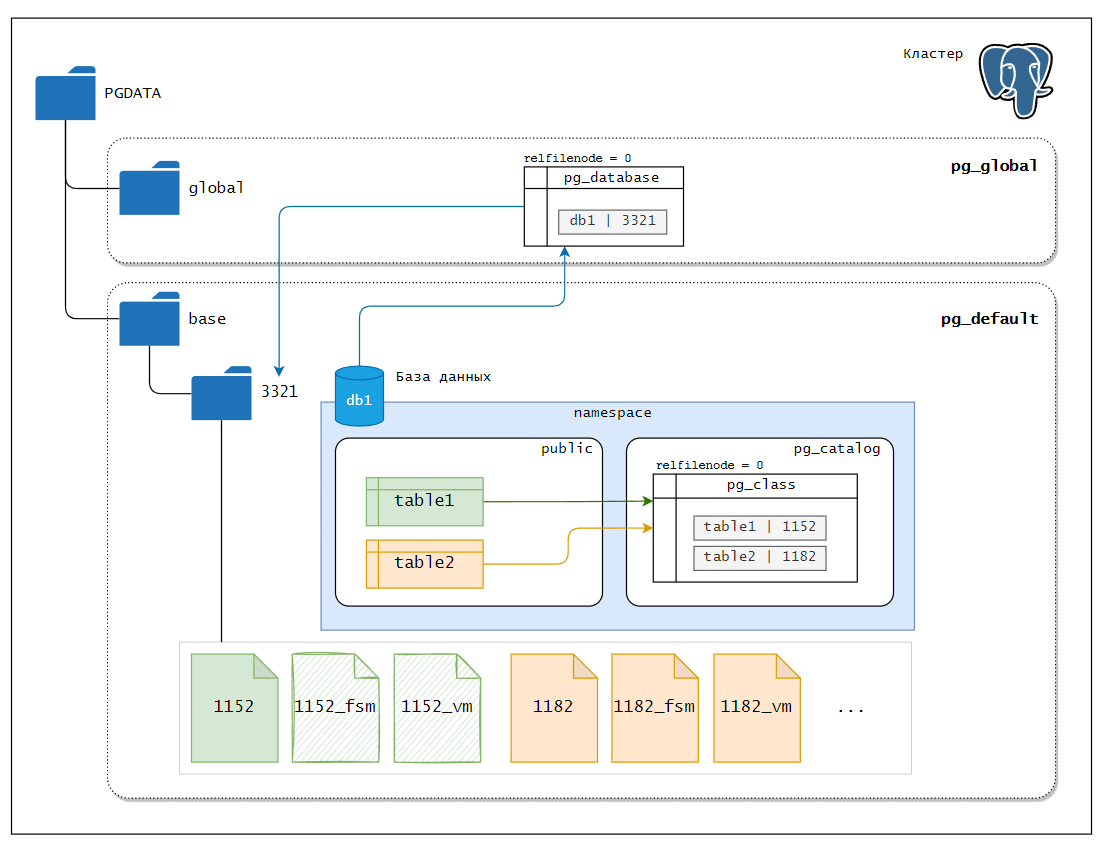
Кластер
Каждый запущенный экземпляр постгри обслуживает одну или несколько баз данных.
Каталог, в котором размещаются все файлы, относящиеся к кластеру, обычно называют словом PGDATA, по имени переменной окружения, указывающей на этот каталог.
При инициализации в PGDATA создаются три одинаковые базы данных:
template0используется, например, для восстановления из логической резервной копии или для создания базы в другой кодировке и никогда недолжна меняться;
template1служит шаблоном для всех остальных баз данных, которые может создать пользователь в этом кластере;
postgresпредставляет собой обычную базу данных, которую можно использовать по своему усмотрению.
Для выполнения команды CREATE DATABASE необходимо подключение к серверу базы данных. Первая база данных всегда создаётся командой initdb при инициализации пространства хранения данных (см. документацию.) Эта база данных называется postgres.
База данных postgres используется пользователями и приложениями для подключения по умолчанию. Представляет собой всего лишь копию template1, и может быть удалена и повторно создана.
template1 является примером для создания остальных баз, поэтому при изменении её, изменения будут касаться остальных созданных баз.
template0 нужна когда нужно создат базу с дефолтными значениями,тк она неизменяема и такая же как начальнео состояние template0
Шаблоны баз данных
По факту команда CREATE DATABASE выполняет копирование существующей базы данных. По умолчанию копируется стандартная системная база template1.
CREATE DATABASE users TEMPLATE template0;
Если в команде CREATE DATABASE указать в качестве шаблона template0 вместо template1, вы сможете получить «чистую» пользовательскую базу данных (в которой никаких пользовательских объектов нет, есть только системные объекты в первозданном виде), не содержащую ничего, что могло быть добавлено на месте в template1 (Рис. 1.3)
Системный каталог
Системные каталоги начинаются с приставки pg_ и хранят метаднные в частности информацию о таблицах и столбцах, а также служебные сведения. Сами по себе это обычные таблицы и к ним моно обращаться через обычные запросы, например pg_database
В отличие от большинства системных каталогов, pg_database разделяется всеми базами данных кластера: есть только один экземпляр pg_database в кластере, а не отдельные в каждой базе данных.
Схема
Схема представляет из себя некое пространство имен для сущностей внутри БД
То есть, нельзя дублировать названия таблиц или функций итд только в рамках схемы.
По дефолту все создается и ищется в схеме public, но схем может быть больше
Также существует схема pg_catalog где хранятся все системные сущности и по умолчанию поиск начинается с этой схемы.
Дефолтный порядок поиска объектов:
- служебные
- Схема с именем пользователя
- public
Табличные пространства.
Табличные пространства определяют физическое расположение данных. Фактически табличное пространство — это каталог файловой системы.
При инициализации кластера создаются два табличных пространства:
pg_defaultрасполагается в каталогеPGDATA/baseи используется как табличное пространство по умолчанию, если явно не выбрать для этой цели другое пространство;
pg_globalрасполагается в каталогеPGDATA/globalи хранит общие для всего кластера объекты системного каталога.
Для создания табличного пространства используется команда CREATE TABLESPACE, например::
CREATE TABLESPACE fastspace LOCATION '/ssd1/postgresql/data';
Табличные пространства могут быть использованы например чтобы хранить что то редко-используемое на медленных носителях, а часто используемомоое на быстрых
Создадим индекс по столбцу в табличном пространстве fastspace:
CREATE INDEX code_idx ON films (code) TABLESPACE fastspace;
Разные БД могу хранить данные в разных табличных пространствах.
Слои и файлы
Внутри каталога PGDATA (На убунте это /var/lib/postgresql/12/main) есть подкаталог base. Этот
каталог и есть табличное пространство base.
Для каждой базы данных в кластере существует подкаталог внутри PGDATA/base (Если только я не создал БД в отдельном табличном пространстве), названный по OID базы данных в pg_database. Этот подкаталог по умолчанию является местом хранения файлов базы данных; в частности, там хранятся её системные каталоги
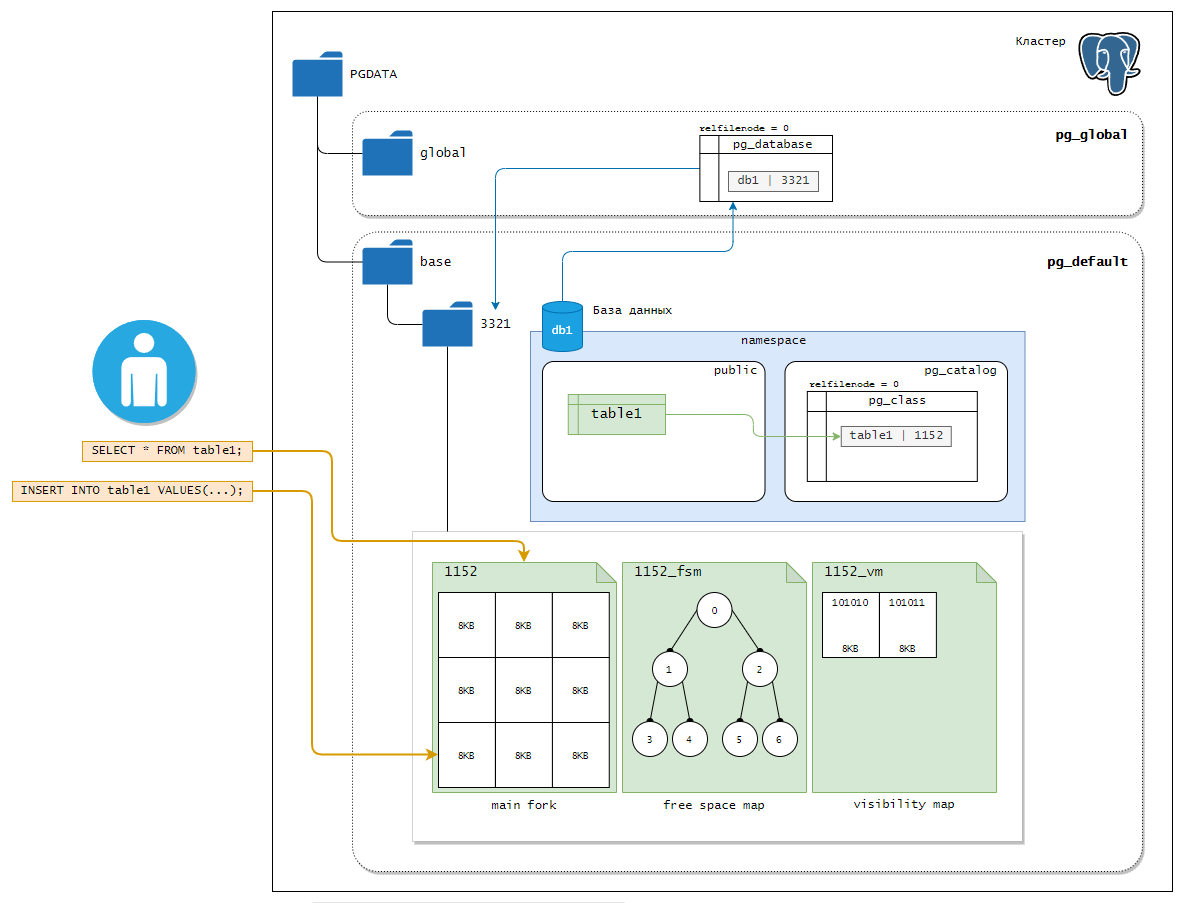
Если перейти в директорию конкретной базы, то там будет много много файлов.
Каждая таблица и индекс хранятся в отдельном файле. Для обычных отношений, эти файлы получают имя по номеру файлового узла таблицы или индекса, который содержится в pg_class.relfilenode
Если relfilenode больше нуля, то файл найти можно, если равно нулю, то либо временное, либо не протоколируемое итд
Где именно хранятся данные для таких таблиц где relfilenode=0 зависит от режима работы PostgreSQL и конфигурации базы данных.

Помимо главного файла (также называемого основным слоем), у каждой таблицы и индекса есть карта свободного пространства (документация). Но появляется она не сразу, а только при необходимости. Имя файла карты свободного пространства образуется из номера файлового узла с суффиксом _fsm.
Также таблицы имеют карту видимости, хранящуюся в слое с суффиксом _vm, она существует для таблиц, но не для индексов (документация)
Когда объём таблицы или индекса превышает 1 GB, они делятся на сегменты размером в один гигабайт (Рис. 1.19). Файл первого сегмента называется по номеру файлового узла (filenode); последующие сегменты получают имена filenode.1, filenode.2 и т. д.
Каждое пользовательское табличное пространство имеет символическую ссылку внутри каталога PGDATA/pg_tblspc.
Ссылка ведет на адрес этого пространства. Каждое пользовательское табличное пространство имеет символическую ссылку внутри каталога PGDATA/pg_tblspc. Внутри физической папки табличного пространства, табличное пространство лежит в папке PG_16_202307071, это есть название версии хоста. Это нужно чтобы разные версии постгри могли использовать одно и то же местоположение, заданное в CREATE TABLESPACE.

Функция pg_relation_filepath() показывает полный путь (относительно PGDATA) для любого отношения.
SELECT pg_relation_filepath('db1.public.new1');
Слои

Существует несколько слоев. Слой это файл. Для удобства организации ввода-вывода файлы логически поделены на страницы (или блоки) — это минимальный объем данных, который считывается или записывается.
- Основной слой (
main fork) — это собственно данные: те самые табличные или индексные строки. Данные разделены на страницы. - Слой инициализации (
init fork) существует только для не журналируемых таблиц (созданных с указанием UNLOGGED) и их индексов. Такие объекты ничем не отличаются от обычных, кроме того, что действия с ними не записываются в журнал предзаписи. За счет этого работа с ними происходит быстрее, но в случае сбоя невозможно восстановить данные в согласованном состоянии. Поэтому при восстановлении PostgreSQL просто удаляет все слои таких объектов и записывает слой инициализации на место основного слоя. В результате получается «пустышка». - Карта свободного пространства (
free space map) — слой, в котором отслеживается примерный объем свободного места внутри страниц. - Карта видимости (
visibility map) — слой, который позволяет быстро определить, требует ли страница очистки или заморозки. Для каждой страницы хранит два бита, требует ли страница заморзки или страница является видимой.
TOAST
TOAST (The Oversized-Attribute Storage Technique, Методика хранения сверхбольших атрибутов).
PostgreSQL использует фиксированный размер страницы (обычно 8 КБ), и не позволяет строчке таблицы занимать несколько страниц.
TOAST подразумевает несколько сценариев действий.
- Он может сжимать данные.
- Он может разбивать строку на подстроки и хранить их в отдельной таблице.
- Может комбинировать эти действия.
Если какие-либо столбцы таблицы хранятся в формате TOAST, у таблицы будет связанная с ней таблица TOAST, OID которой хранится в значении pg_class.reltoastrelid
Код обработки TOAST распознаёт четыре различные стратегии хранения столбцов, совместимых с TOAST, на диске:
PLAINне допускает ни сжатия, ни отдельного хранения. Это единственно возможная стратегия для столбцов типов данных, которые несовместимы с TOAST.
EXTENDEDдопускает как сжатие, так и отдельное хранение. Это стандартный вариант для большинства типов данных, совместимых с TOAST. Сначала происходит попытка выполнить сжатие, затем — сохранение вне таблицы, если строка всё ещё слишком велика.
EXTERNALдопускает отдельное хранение, но не сжатие. ИспользованиеEXTERNALускорит операции над частями строк в больших столбцахtextиbytea(ценой увеличения объёма памяти для хранения), так как эти операции оптимизированы для извлечения только требуемых частей отделённого значения, когда оно не сжато.
MAINдопускает сжатие, но не отдельное хранение. (Фактически для таких столбцов будет тем не менее применяться отдельное хранение, но лишь как крайняя мера, когда нет другого способа уменьшить строку так, чтобы она помещалась на странице.)